
To convert a date string into a timestamp in Java, you can use built-in methods like “SimpleDateFormat.parse()” and “Timestamp.valueOf()”.
Java

How to Write Data to a CSV File in Java
Use the built-in classes like FileWriter, PrintWriter, or BufferedWriter to write data to a CSV file in Java. Also, you can use some third-party libraries.

How to Create a List in Java
You can create a list in Java using the new operator, Arrays.asList(), List.of(), or Stream.of() and Collectors.toList() methods.

Java Unary Operator | Explained With Examples
Java unary operators require only one operand to perform any task. These operators include increment, decrement, bitwise complement, etc.
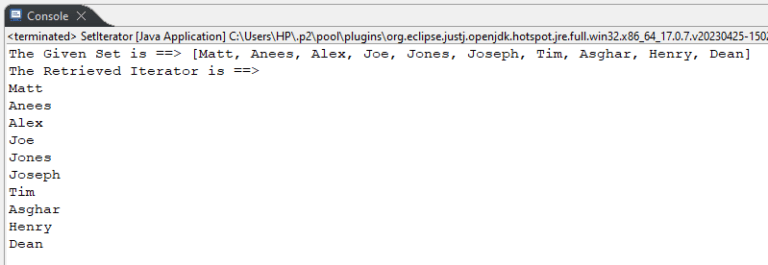
How to Use Set iterator() Method in Java
In Java, iterator() is an in-built method of the set interface that loops through a set and retrieves the iterator/values.

How to Use Math.random() in Java
“Math.random()” is a built-in static method of the “java.util.Math” class that generates a pseudorandom number between the range “0.0” and “1.0”.

How to Move a File Using Java
To move a file using Java, use built-in methods like “move()” and “renameTo()” or third-party libraries like Guava and Apache Commons.

How to Remove Character From a String in Java
To remove a character from a string in Java, you can use built-in methods like replace(), substring(), deleteCharAt(), or delete().